Lab1:基础五级流水线¶
1 实验目的¶
- 理解流水线的基本概念与思想
- 基于在单周期 CPU 中已经实现的模块,实现 5 级流水线框架
- 理解流水线设计在提高 CPU 的吞吐率,提升整体性能上的作用与优越性
2 实验环境¶
- HDL:Verilog SystemVerilog
- IDE:Vivado
- 开发板:Nexys A7
- 提供测试程序和测试框架
3 实验背景¶
在同一时刻下,流水线的五个流水级运行的指令实际各不相同。 因此,我们一般将一条指令所需的控制信号一起存在流水段间寄存器中,随指令其他信息一起顺着流水线传递,这里的段间寄存器是指:IF/ID 寄存器、 ID/EX 寄存器、EX/MEM 寄存器、MEM/WB 寄存器这四个用于流水段间传递指令信息的寄存器组。
以 add 指令为例。该指令在 ID 阶段对指令解码,得到所使用的寄存器rd ,rs1 , rs2。 但由于寄存器组写回需要等待到 WB 阶段,于是需要段间寄存器存储 rd 的值,一级一级流水传递到 WB 阶段。原则上每一拍过后,流水线都会向前流动一段。
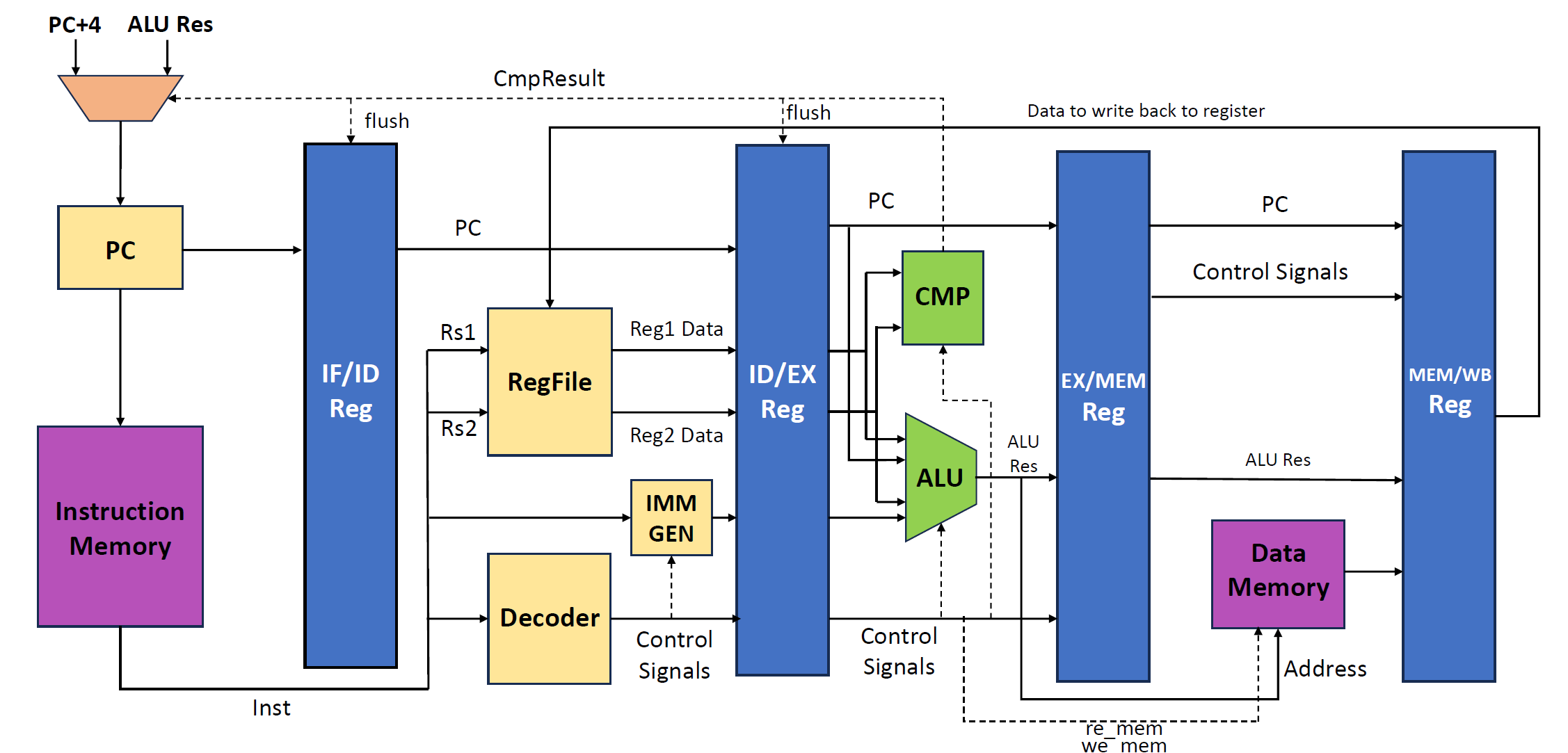
第 x 拍 IF 阶段发起取指令的请求,第 x+1 拍取得该指令并流入 ID 段进行译码,例如译码得到的是 lw 指令,那么第 x+2 拍流入 EX 段内指令 lw 完成地址计算,第 x+3 拍 lw 流入 MEM 段完成访存的读取,第 x+4 拍流入 WB 阶段将访存中的值写回寄存器组。下表展示了一个简单的顺序执行的指令序列是如何在流水线的各个流水级中流淌的。
| time | IF | ID | EX | MEM | WB/commit |
|---|---|---|---|---|---|
| cycle1 | Fetching inst1 | / | / | / | / |
| cycle2 | Fetching inst2 | inst1 | / | / | / |
| cycle3 | Fetching inst3 | inst2 | inst1 | / | / |
| cycle4 | Fetching inst4 | inst3 | inst2 | inst1 | / |
| cycle5 | Fetching inst5 | inst4 | inst3 | inst2 | inst1 |
| cycle6 | Fetching inst6 | inst5 | inst4 | inst3 | inst2 |
| cycle7 | ... | ... | ... | ... | ... |
4 实验要求¶
在 SCPU 的基础上加入中间寄存器实现五级流水线 CPU,处理器要求支持 RV64I 指令集,要求实现的完整指令列表如下:
- [ ]
lui, auipc - [ ]
jal, jalr - [ ]
beq, bne, blt, bge, bltu, bgeu - [ ]
lb, lh, lw, lbu, lhu, lwu, ld, sb, sh, sw, sd - [ ]
addiw, slliw, srliw, sraiw - [ ]
addw, subw, sllw, srlw, sraw - [ ]
addi, slti, sltiu, xori, ori, andi, slli, srli, srai - [ ]
add, sub, sll, slt, sltu, xor, srl, sra, or, and
5 实验步骤¶
5.1 实现基础五级流水线¶
我们依然按照最基本的IF,ID,EXE,MEM,WB五个阶段来说明流水线CPU的实现,重点会放在与单周期CPU的区分上,即衔接段的处理和段间一些不同的操作。
首先很重要的准备工作是段间寄存器组的引入,即IF/ID 寄存器、 ID/EX 寄存器、EX/MEM 寄存器、MEM/WB 寄存器这四个用于流水段间传递指令信息的寄存器组。由于提供了相应的PipelinePack包,实现上并不复杂:
这儿需要注意的是每个段间的一对寄存器组分别表示当前周期流水段寄存器中已经存储的值和组合逻辑计算出的下一拍要写入的值。具体来讲,*_r 寄存器组继承上一个周期 latched 下来的值,表示寄存后的稳定状态;*_n 寄存器组存储本周期逻辑推算的结果,作为下一个周期的候选值,准备在时钟上升沿写入*_r寄存器。
5.1.1 IF阶段¶
IF阶段结合实验设计做了很重要的一个妥协,上述所提的标准的流水线设计在第1拍拿到指令,第2拍传给ID,但由于握手延迟和stall机制尚未引入,我们的第1拍实际只完成了握手这一个过程,真正的IF和ID在第二拍统一完成,实际将Instruction Memory取出来的指令直接传进了ID阶段。具体代码实现如下:
inst_t inst_if;
assign inst_if=pc_req[2]?imem_ift.r_reply_bits.rdata[63:32] :imem_ift.r_reply_bits.rdata[31:0];
inst_t inst_id;
assign inst_id=inst_if;
这里引入的pc_req寄存器实现了流水线段间寄存器一拍的延迟,抵消了握手消耗的时间。需要注意的是,为了规范性的要求和考虑后续实验的设计,我们保留了inst_if 寄存器,这样尽管引入了不必要的接线,但是在代码结构上更加清晰和易于维护扩展。
同样的,我们保留了IF/ID 段的衔接处理,值得一提的是由于妥协机制,IF/ID段实际上不存在时序上的衔接逻辑,我们实际上弃用了IF/ID寄存器组的两个inst寄存器,但为了后续代码的改动还是保留了正常的更新逻辑。
always @(*) begin
ifid_n.pc = pc_req;
ifid_n.pc_4 = pc_req + 64'd4;
ifid_n.inst = inst_if;
ifid_n.valid = 1'b1;
end
5.1.2 ID阶段¶
为了追求更加简洁的代码风格,我们还是采用了ControllerPack包,控制单元的具体实现和单周期CPU是完全一致的不做赘述。同样位于ID阶段的RegFile寄存器堆访问读值和IMM立即数生成也没有变化。
完成上述处理后,我们来到了和EXE阶段的衔接段;由于在IF/ID衔接段所采取的简化措施,到这里实际上才第一次真正面对段间寄存器的传值问题。我们把ID得到的译码结果放进idexe_n 寄存器中来提供下一拍的EXE段需要的更新信息,实现接线如下:
always @(*) begin
idexe_n.we_reg = ctrl_signals.we_reg;
idexe_n.we_mem = ctrl_signals.we_mem;
idexe_n.re_mem = ctrl_signals.re_mem;
idexe_n.npc_sel = ctrl_signals.npc_sel;
idexe_n.imm = imm_id;
idexe_n.alu_op = ctrl_signals.alu_op;
idexe_n.cmp_op = ctrl_signals.cmp_op;
idexe_n.alu_a_sel = ctrl_signals.alu_a_sel;
idexe_n.alu_b_sel = ctrl_signals.alu_b_sel;
idexe_n.reg_data_1 = read_data_1;
idexe_n.reg_data_2 = read_data_2;
idexe_n.wb_sel = ctrl_signals.wb_sel;
idexe_n.mem_op = ctrl_signals.mem_op;
idexe_n.rd = rd_id;
idexe_n.rs1 = rs1_id;
idexe_n.rs2 = rs2_id;
idexe_n.pc = pc_req;
idexe_n.pc_4 = pc_req + 64'd4;
idexe_n.inst = inst_id;
idexe_n.valid = ifid_r.valid;
end
5.1.3 EXE阶段¶
来到EXE阶段,同单周期CPU一样,我们根据当前ID/EXE寄存器中的译码结果进行ALU操作数的选择,并连同译出的操作符一起送入ALU中,生成的ALU结果也进行了LSB清零。同样的Cmp也是一样的处理,判断出是否进行跳转后对于next_pc进行选择赋值,不做赘述。
随后是我们第二个重要的妥协处理,我们将访存的工作前移到EX阶段,这样来保证在 MEM 阶段直接拿到访存数据而不用因为握手延迟。那么相应的数据打包和掩码生成也需要提前到该阶段完成,随后将访存地址与访存使能信号传到 Data Memory 开始握手。
mask_t mask_package_ex;
data_t data_package_ex;
MaskGen u_mask (
.mem_op(idexe_r.mem_op),
.dmem_waddr(alu_res_ex),
.dmem_wmask(mask_package_ex)
);
DataPkg u_datapkg (
.mem_op(idexe_r.mem_op),
.reg_data(idexe_r.reg_data_2),
.dmem_waddr(alu_res_ex),
.dmem_wdata(data_package_ex)
);
always @(*) begin
dmem_ift.r_request_bits.raddr = alu_res_ex;
dmem_ift.r_request_valid = idexe_r.re_mem;
dmem_ift.r_reply_ready = 1'b1;
dmem_ift.w_request_bits.waddr = alu_res_ex;
dmem_ift.w_request_bits.wdata = data_package_ex;
dmem_ift.w_request_bits.wmask = mask_package_ex;
dmem_ift.w_request_valid = idexe_r.we_mem;
dmem_ift.w_reply_ready = 1'b1;
end
在EX/MEM衔接段,我们做一样的处理,把EXE得到的执行结果放进exmem_n寄存器中来提供下一拍的MEM段需要的更新信息。
always @(*) begin
exemem_n.we_reg = idexe_r.we_reg;
exemem_n.we_mem = idexe_r.we_mem;
exemem_n.re_mem = idexe_r.re_mem;
exemem_n.br_taken = br_taken_ex;
exemem_n.alu_res = alu_res_ex;
exemem_n.reg_data_1 = idexe_r.reg_data_1;
exemem_n.reg_data_2 = idexe_r.reg_data_2;
exemem_n.mem_wdata = data_package_ex;
exemem_n.wb_sel = idexe_r.wb_sel;
exemem_n.mem_op = idexe_r.mem_op;
exemem_n.rd = idexe_r.rd;
exemem_n.rs1 = idexe_r.rs1;
exemem_n.rs2 = idexe_r.rs2;
exemem_n.pc = idexe_r.pc;
exemem_n.pc_4 = idexe_r.pc_4;
exemem_n.npc = next_pc;
exemem_n.inst = idexe_r.inst;
exemem_n.valid = idexe_r.valid;
end
5.1.4 MEM阶段¶
由于前提了掩码生成和数据打包操作,在当前的MEM阶段我们只用对于读到的数据进行截取和扩展。
data_t data_trunc_mem;
DataTrunc u_trunc (
.dmem_rdata(dmem_ift.r_reply_bits.rdata),
.mem_op(exemem_r.mem_op),
.dmem_raddr(exemem_r.alu_res),
.read_data(data_trunc_mem)
);
MEM/WB衔接段继续实现段间寄存器值的传递,不做赘述,仅给出实现:
always @(*) begin
memwb_n.we_reg = exemem_r.we_reg;
memwb_n.re_mem = exemem_r.re_mem;
memwb_n.br_taken = exemem_r.br_taken;
memwb_n.mem_we = {63'b0, exemem_r.we_mem};
memwb_n.alu_res = exemem_r.alu_res;
memwb_n.data_trunc = data_trunc_mem;
memwb_n.read_data_1= exemem_r.reg_data_1;
memwb_n.read_data_2= exemem_r.reg_data_2;
memwb_n.mem_wdata = exemem_r.mem_wdata;
memwb_n.mem_rdata = dmem_ift.r_reply_bits.rdata;
memwb_n.mem_addr = exemem_r.alu_res;
memwb_n.wb_sel = exemem_r.wb_sel;
memwb_n.rd = exemem_r.rd;
memwb_n.rs1 = exemem_r.rs1;
memwb_n.rs2 = exemem_r.rs2;
memwb_n.pc = exemem_r.pc;
memwb_n.pc_4 = exemem_r.pc_4;
memwb_n.npc = exemem_r.npc;
memwb_n.inst = exemem_r.inst;
memwb_n.valid = exemem_r.valid;
end
5.1.5 WB阶段¶
根据wb_sel寄存器的结果进行写回,具体的写和单周期CPU相同在寄存器堆中实现了,不做赘述。
5.1.6 段间寄存器和PC更新¶
在单周期CPU中,我们只需要考虑PC信号的跳转,然而由于流水线CPU引入了段间寄存器,使得其需要更复杂的时序逻辑进行更新,因此作为单独模块讲解。首先对于复位信号,我们要把段间寄存器赋默认值,实现如下:
always @(posedge clk or posedge rst)
if (rst) begin
pc <= '0;
pc_req <= '0;
ifid_r <= '{default:'0};
idexe_r <= '{
we_reg:1'b0,
we_mem:1'b0,
re_mem:1'b0,
npc_sel:1'b0,
imm:'0,
alu_op:ALU_DEFAULT,
cmp_op:CMP_NO,
alu_a_sel:ASEL_REG,
alu_b_sel:BSEL_REG,
reg_data_1:'0,
reg_data_2:'0,
wb_sel:WB_SEL_ALU,
mem_op:MEM_NO,
rd:'0,
rs1:'0,
rs2:'0,
pc:'0,
pc_4:'0,
inst:'0,
valid:1'b0
};
exemem_r <= '{
we_reg:1'b0,
we_mem:1'b0,
re_mem:1'b0,
br_taken:1'b0,
alu_res:'0,
reg_data_1:'0,
reg_data_2:'0,
mem_wdata:'0,
wb_sel:WB_SEL_ALU,
mem_op:MEM_NO,
rd:'0,
rs1:'0,
rs2:'0,
pc:'0,
pc_4:'0,
npc:'0,
inst:'0,
valid:1'b0
};
memwb_r <= '{
we_reg:1'b0,
re_mem:1'b0,
br_taken:1'b0,
mem_we:'0,
alu_res:'0,
data_trunc:'0,
read_data_1:'0,
read_data_2:'0,
mem_wdata:'0,
mem_rdata:'0,
mem_addr:'0,
wb_sel:WB_SEL_ALU,
rd:'0,
rs1:'0,
rs2:'0,
pc:'0,
pc_4:'0,
npc:'0,
inst:'0,
valid:1'b0
};
end
那么对于一般情况,只要使*_r 寄存器组继承*_n 寄存器组的值实现更新,但是在EXE阶段计算出跳转后,我们将IF/ID,ID/EXE寄存器组还原到默认状态重新开始运转;同时引入flush机制,从而无效掉中间流水段的nop指令的提交,表现在代码上为拉低了valid信号,具体实现如下:
pc <= next_pc;
pc_req <= pc;
ifid_r <= (br_taken_ex) ? '{pc:pc, pc_4:pc_4, inst:'0, valid:1'b0} : ifid_n;
idexe_r <= (br_taken_ex) ? '{
we_reg:1'b0,
we_mem:1'b0,
re_mem:1'b0,
npc_sel:1'b0,
imm:'0,
alu_op:ALU_DEFAULT,
cmp_op:CMP_NO,
alu_a_sel:ASEL_REG,
alu_b_sel:BSEL_REG,
reg_data_1:'0,
reg_data_2:'0,
wb_sel:WB_SEL_ALU,
mem_op:MEM_NO,
rd:'0,
rs1:'0,
rs2:'0,
pc:'0,
pc_4:'0,
inst:'0,
valid:1'b0
} : idexe_n;
exemem_r<= exemem_n;
memwb_r <= memwb_n;
end
5.1.7 cosim信号接线¶
为了仿真检验结果的正确性,区分于单周期cpu的始终拉高cosim_valid 保持检验,我们只有在最后一个校验信号被拉高时才开启校验(前几拍由于WB还没有数据传入是无效的否则会报错)其他的接线与单周期CPU相似,给出具体实现。
assign cosim_valid = memwb_r.valid;
assign cosim_core_info.pc = memwb_r.pc;
assign cosim_core_info.inst = {32'b0, memwb_r.inst};
assign cosim_core_info.rs1_id = {59'b0, memwb_r.rs1};
assign cosim_core_info.rs1_data = memwb_r.read_data_1;
assign cosim_core_info.rs2_id = {59'b0, memwb_r.rs2};
assign cosim_core_info.rs2_data = memwb_r.read_data_2;
assign cosim_core_info.alu = memwb_r.alu_res;
assign cosim_core_info.mem_addr = memwb_r.mem_addr;
assign cosim_core_info.mem_we = memwb_r.mem_we;
assign cosim_core_info.mem_wdata= memwb_r.mem_wdata;
assign cosim_core_info.mem_rdata= memwb_r.mem_rdata;
assign cosim_core_info.rd_we = {63'b0, do_write};
assign cosim_core_info.rd_id = {59'b0, memwb_r.rd};
assign cosim_core_info.rd_data = wb_val;
assign cosim_core_info.br_taken = {63'b0, memwb_r.br_taken};
assign cosim_core_info.npc = memwb_r.npc;
5.2 仿真¶
执行make verilate TESTCASE=syn CUSTOM_OPTS=-DNORACE进行仿真测试,仿真结果和示例相一致,说明了流水线CPU的基本功能校验正确。
5.3 综合下板¶
执行make board_sim TESTCASE=syn CUSTOM_OPTS=-DNORACE 生成测试文件,死循环在0x2b0 处证明通过。
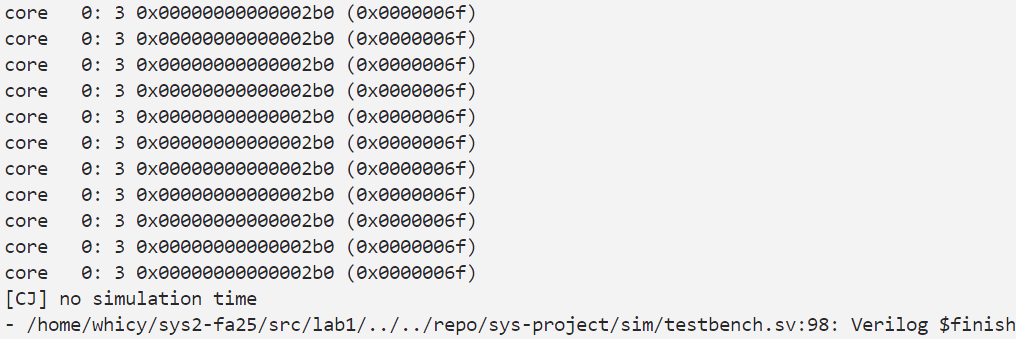
进行综合、构建后生成比特流,进行上板测试,处理器死循环在0x2b0 ,说明实验成功,至此完成流水线CPU的完整搭建。尝试调整时钟频率,经过下板测试,在150MHz时保持正常工作,在160MHz工作时出现报错,证明其极限频率为150MHz左右。

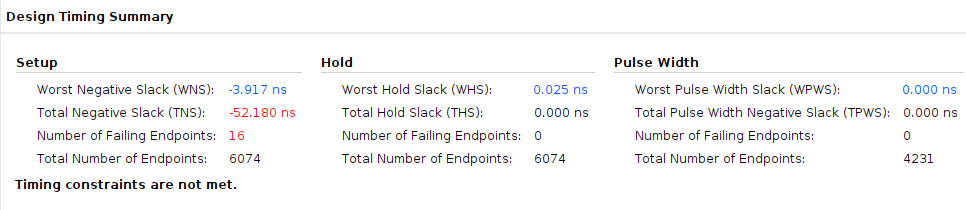
在这里对极限频率的测试做一个声明,为了避免每次都需要生成比特流并下板验证,我们每次在更改时钟频率后可以仅进行综合构建,每次构建完成后可以查看Design Timing Summary中的Worst Negative Slack。这个参数表示在当前的时钟约束下的时序裕量,那么最快路径的传播延迟就可以通过\(T_{period}-WNS\)计算得到,我们设置T_period=6.667ns,此时时钟频率为150MHz,可以看到时序满足,继续调整时钟周期来增大频率。
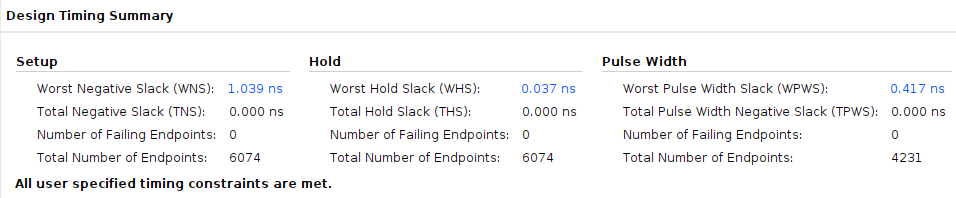
设置T_period=6.250ns,时钟频率为160MHz,此时注意到WNS<0,并出现了不满足时序的端点,证明其极限频率为150~160MHz,下板同样验证了这一结果。
6 思考题¶
-
对于
syn.asm的fibonacci的如下代码段,请计算该 loop 在流水线 CPU、SCPU、多周期 CPU 各自的 CPI,对比三者的 CPI。20%000000000000000c <fibonacci>: c: 00000013 addi zero,zero,0 10: 00000013 addi zero,zero,0 14: 002081b3 add gp,ra,sp 18: 00000013 addi zero,zero,0 1c: 00000013 addi zero,zero,0 20: 00000013 addi zero,zero,0 24: 003100b3 add ra,sp,gp 28: 00000013 addi zero,zero,0 2c: 00000013 addi zero,zero,0 30: 00000013 addi zero,zero,0 34: 00308133 add sp,ra,gp 38: fff20213 addi tp,tp,-1 # ffffffffffffffff <_end+0xfffffffffffffccf> 3c: 00000013 addi zero,zero,0 40: 00000013 addi zero,zero,0 44: 00000013 addi zero,zero,0 48: fc4012e3 bne zero,tp,c <fibonacci>一共有16条指令(3条R型的add指令,12条I型指令,1条B型指令),我们考虑三种CPU执行它们需要的周期数。
对于SCPU,由于每条指令都在单周期内执行,一共需要16个周期,CPI=1;
对于多周期CPU,我们参考系统I bonus的设计思路,认为非访存指令为 3 周期,访存指令为 4 周期,则合计周期数为\((12+3)\times 4=63\)周期,CPI=3.9375
对于流水线CPU,由于我们采用的妥协机制,两次握手(对于第一次握手,相当于占据了本来的ID段;第二次握手前提到EX段)被段寄存器掩蔽了,唯一的损耗来自分支被采纳时flush掉的IF/ID两个周期,假设一共跑N次迭代,则被采纳的分支数为N-1(最后一次不采纳),那么总的周期数为\(16N+2(N-1)\)\(CPI=1.125-\frac1{8N}\approx1.125\)
-
假设 SCPU 的时钟频率是 100 MHz,如果流水线想要有比单周期 CPU 更高的执行效率,它的时钟频率至少需要是多少?10%
我们考虑流水线的吞吐率\(IPC=\frac{f_{pipe}}{CPI_{pipe}}>100MHz\),我们采用上述特定代码段的时钟频率CPI=1.125,计算得到\(f_{pipe-min}=112.5MHz\)
-
从时钟频率和 CPI 的角度解释,为什么多周期 CPU 优于单周期 CPU,流水线 CPU 优于多周期 CPU。10%
多周期 CPU 之所以优于单周期 CPU,是因为单周期 CPU 的时钟周期必须足够长以覆盖最慢指令的所有阶段,导致频率偏低,即使 CPI 为 1 也难以发挥效率。而多周期 CPU 将一条指令拆分为多个更短的阶段执行,时钟周期只需满足单个子阶段的延迟,因此频率更高,虽然 CPI 大于 1,但整体执行时间往往更短,平均性能优于单周期 CPU。
流水线 CPU 之所以优于多周期 CPU,则在于它在分段执行的基础上进一步并行化了不同指令的各个阶段,使得多条指令可以在同一时刻重叠进行。流水线的时钟周期同样由最慢的一个阶段决定,比多周期更短,同时 CPI 接近 1,仅在分支或冒险时略有增加,因此既保持了较高的时钟频率,又降低了平均 CPI,整体执行效率远超多周期 CPU。